Google's Secure AI Framework (SAIF)¶
Overview¶
An additional framework covering security risks in AI applications is Google's Secure AI Framework (SAIF). It provides actionable principles for secure development of the entire AI pipeline - from data collection to model deployment. While SAIF provides a list of security risks similar to OWASP, it goes even further and provides a holistic approach to developing secure AI applications. This includes the integration of security and privacy in the entire AI pipeline. OWASP provides a targeted, technical checklist of vulnerabilities, whereas SAIF offers a broader perspective on secure AI development as a whole.
SAIF Areas and Components¶
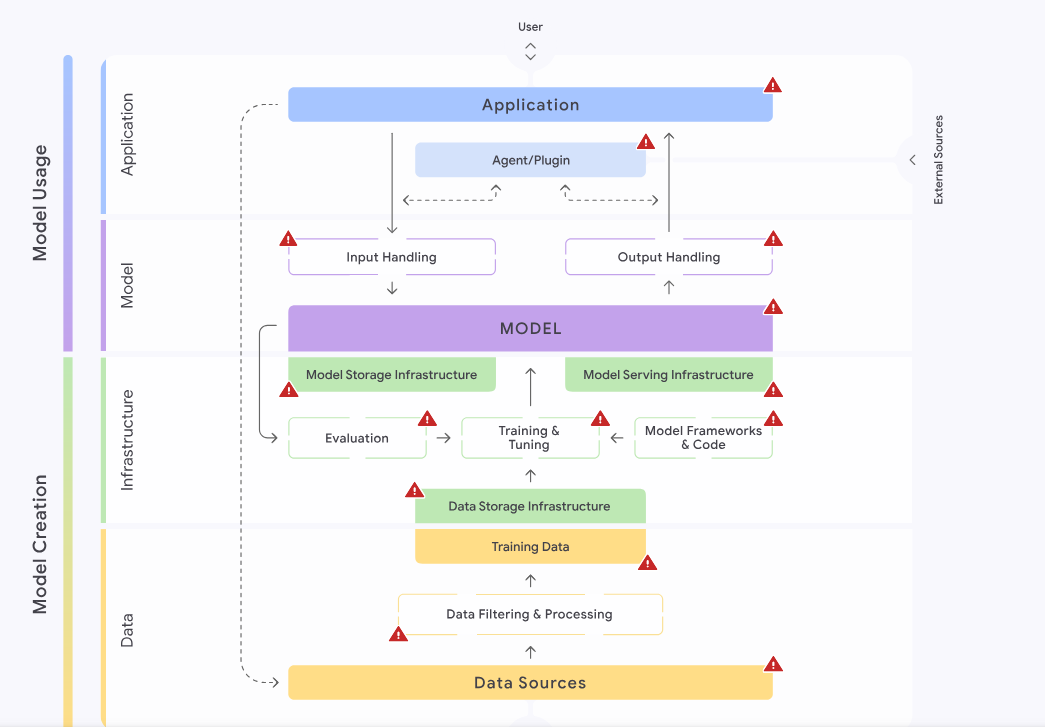
In SAIF, there are four different areas of secure AI development. Each comprises multiple components:
Data: This area consists of all components relating to data such asdata sources,data filtering and processing, andtraining data.Infrastructure: This area relates to the hardware on which the application is hosted, as well as data storage and development platforms. Infrastructure components are theModel Frameworks and Coderequired to run the AI application, the processes ofTraining, Tuning, and Evaluation,Data and Model Storage, and the process of deploying a model (Model Serving).Model: This is the central area of any AI application. It comprises theModel,Input Handling, andOutput Handlingcomponents.Application: This area relates to the interaction with the AI application, i.e., it consists of theApplicationsinteracting with the AI deployment and potentialAgentsorPluginsused by the AI deployment.
We will use a similar categorization throughout this module and the remainder of the AI Red Teamer path.
SAIF Risks¶
Like OWASP's Top 10, SAIF describes concrete security risks that may arise in AI applications. Here is an overview of the risks included in SAIF. Many are also included in OWASP's ML Top 10 or LLM Top 10:
Data Poisoning: Attackers inject malicious or misleading data into the model's training data, compromising performance or creating backdoors.Unauthorized Training Data: The model is trained on unauthorized data, resulting in legal or ethical issues.Model Source Tampering: Attackers manipulate the model's source code or weights, compromising performance or creating backdoors.Excessive Data Handling: Data collection or retention goes beyond what is allowed in the corresponding privacy policies, resulting in legal issues.Model Exfiltration: Attackers gain unauthorized access to the model itself, stealing intellectual property and potentially causing financial harm.Model Deployment Tampering: Attackers manipulate components used for model deployment, compromising performance or creating backdoors.Denial of ML Service: Attackers feed inputs to the model that result in high resource consumption, potentially causing disruptions to the ML service.Model Reverse Engineering: Attackers gain unauthorized access to the model itself by analyzing its inputs and outputs, stealing intellectual property, and potentially causing financial harm.Insecure Integrated Component: Attackers exploit security vulnerabilities in software interacting with the model, such as plugins.Prompt Injection: Attackers manipulate the model's input directly or indirectly to cause malicious or illegal behavior.Model Evasion: Attackers manipulate the model's input by applying slight perturbations to cause incorrect inference results.Sensitive Data Disclosure: Attackers trick the model into revealing sensitive information in the response.Inferred Sensitive Data: The model provides sensitive information that it did not have access to by inferring it from training data or prompts. The key difference to the previous risk is that the model does not have access to the sensitive data but provides it by inferring it.Insecure Model Output: Model output is handled insecurely, potentially resulting in injection vulnerabilities.Rogue Actions: Attackers exploit insufficiently restricted model access to cause harm.
SAIF Controls¶
SAIF specifies how to mitigate each risk and who is responsible for this mitigation. The party responsible can either be the model creator, i.e., the party developing the model, or the model consumer, i.e., the party using the model in an AI application. For instance, if HackTheBox used Google's Gemini model for an AI chatbot, Google would be the model creator, while HackTheBox would be the model consumer. These mitigations are called controls. Each control is mapped to one of the previously discussed risks. For instance, here are a few example controls from SAIF:
Input Validation and Sanitization: Detect malicious queries and react appropriately, for instance, by blocking or restricting them.- Risk mapping:
Prompt Injection - Implemented by:
Model Creators, Model Consumers
- Risk mapping:
Output Validation and Sanitization: Validate or sanitize model output before processing by the application.- Risk mapping:
Prompt Injection, Rogue Actions, Sensitive Data Disclosure, Inferred Sensitive Data - Implemented by:
Model Creators, Model Consumers
- Risk mapping:
Adversarial Training and Testing: Train the model on adversarial inputs to strengthen resilience against attacks.- Risk mapping:
Model Evasion, Prompt Injection, Sensitive Data Disclosure, Inferred Sensitive Data, Insecure Model Output - Implemented by:
Model Creators, Model Consumers
- Risk mapping:
We will not discuss all SAIF controls here, feel free to check out the remaining controls here.
SAIF Risk Map¶
The Risk Map is the central SAIF component encompassing information about components, risks, and controls in a single place. It provides an overview of the different components interacting in an AI application, the risks that arise in each component, and how to mitigate them. Furthermore, the map provides information about where a security risk is introduced (risk introduction), where the risk may be exploited (risk exposure), and where a risk may be mitigated (risk mitigation).